

公開日:2025年9月22日
生成AIの業務適用 はじめの一歩 ~RAG環境構築~
近年、生成AIは加速度的なスピードで進歩を続けています。
しかしながら、先日総務省から発表された『令和7年版情報通信白書』では、生成AIの業務活用を方針として掲げている日本企業は約50%にとどまっていると示されています。また、大手コンサルティングファームによる調査レポートでは、実際に生成AIを業務に導入している企業のうち、期待以上または期待どおりの効果を得られているとしている企業の割合も50%前後と報告されています。
これらのことから、日本国内において生成AIを業務に導入し、かつ期待した効果を得られている企業はまだ 限定的であることがわかります。
それでは、生成AIの業務適用の壁となっているものは何でしょうか。
導入前の業務の棚卸やデータの準備、導入後の活用方法等に対応するノウハウ、 人材不足等があげられます。
また、 導入に積極的な企業でも、生成AIが出力する情報の正確性や機密情報のセキュリティリスクなどの面で二の足を踏んでいるところも多いと思います。
そこで、生成AIが出力する情報の正確性を向上させる手法のひとつとして注目されているのがRAGです。
RAGは、生成AIが事前学習していない最新のデータや、社内/組織に蓄積された固有の情報を活用することができるため、企業における生成AI利用に必須のものになりつつあります。
本コラムでは、企業が生成AIを業務適用し、成果を上げるための手段の一つであるRAG環境の構築について、当社が実施したPoC(Proof of Concept:概念実証)を通じて得られた成果をご紹介します。
RAGとは
RAGとは、Retrieval Augmented Generationの頭文字で、大規模言語モデル(Large Language Model、以下LLM)と検索機能を組み合わせた、生成AIの回答正確性を増す手法のひとつです。
LLMは、大量の学習データと膨大な量のパラメーターによって構築された自然言語処理に特化したモデルで、それまでの言語モデルと比べ、精度が格段に向上しました。しかし、人のような自然な言語・文章の生成を得意とする一方で、事前学習済みのデータに依存するため、最新データや固有情報を基にした回答を生成するには再学習やファインチューニングという追加学習が必要となります。
これに対しRAGは、外部データから必要な情報を探し出してLLMに参照させることができ、学習時点で含まれていない最新データや社内固有の情報を基に生成・回答できるのが特長です。セキュアなRAG環境を構築することで、社内に蓄積された文書やデータベースなど機密情報を利用した正確性の高い回答を生成AIから得られるようになります。
RAGの仕組み

図1 RAGの仕組み
RAGは大きく分けて、検索(Retrieval)と生成(Generation)の2つのフェーズで構成されます。
まず、ユーザーの質問を受けて必要な情報を検索し、質問に検索結果を加えてLLMに与え文章を生成することで、あたかもLLMの能力を拡張したような回答が得られるようになります。
「拡張」とは、元々は検索によるプロンプト拡張(Retrieval-Augmented)を指しましたが、RAGによる回答正確性の認識が広まるにつれ、拡張生成(Augmented Generation)の意味でも使用されています。
RAGの基本的な仕組み
① Retrieval(検索)フェーズ
ユーザーの質問を外部データで構築されたデータベースで検索し、関連情報を得る工程です。得られた検索結果はコンテキスト情報の一部として、ユーザーの質問(プロンプト)と併せてLLMに入力されます。 コンテキスト情報とは、正確性の高い回答を生成するための背景や根拠などの関連情報です。
② Generation(生成)フェーズ
検索結果により拡張されたプロンプトを基にLLMが回答を作成します。
ここでは、検索で取り出した外部データに基づきLLMが回答を生成するため、より正確性の高い文章が生成されます。
RAGのメリット、デメリット
RAGは、
- ・古いデータや予測により生成AIが回答してしまうハルシネーションが起きにくい
- ・LLMに専門知識や企業/組織固有の情報を活用した回答を生成させることができる
- ・LLMに最新情報を学習させるための再学習/ファインチューニングなどの学習コストが不要
- ・LLMの回答に検索結果の提示(グラウンディング)を含めることができ、LLMの回答が検証可能となる
- などのメリットがあります。
一方、 - ・システム構築が複雑になり、推論コストが増加傾向にある
- ・外部データの品質に依存する
- ・検索がヒットしない場合、LLMが回答できないことがある(ハルシネーションを起こさないためのメリットでもある)
- などのデメリットもあります。
RAGの活用例
現在、RAGの特性を活かした様々な業務利用が展開されています。
■問い合わせ対応
社内・社外からの問い合わせに対し、社内に蓄積された文書や回答例を基に回答
チャットボットの使用も可能
■人材育成
開発事例やノウハウなど、過去の情報を迅速に取得
■マーケティング・市場調査
最新の情報と顧客データを組み合わせたデータの収集・分析
当社で実施した生成AI PoC
背景
当社では、組込み機器向けグラフィックオーサリングツールやHMI開発を含むUI/UXソリューションをお客様へ提供しています。
開発部門では、ベテラン技術者の高齢化とともに、社内・社外から問い合わせや新任エンジニアのトレーニングに対するリソース不足が課題となっていました。生成AIによる課題解決を検討する過程で、RAG環境の構築方法が重要と判断し、PoCの実施を決定しました。
PoCの目的と目標
- 目的:生成AIの業務適用を前提としたRAG環境の構築を通して、ノウハウの蓄積と適用領域を判断する
目標:生成AIを適用する業務を「社内問い合わせ対応」と「開発アイテムの進捗状況確認」と仮定し、RAGをどのように構築すれば業務適用レベルの回答を得られるかを確認する
期間
3ヶ月
使用ツール
Google CloudのVertex AI Agent Builder(現AI Applications)
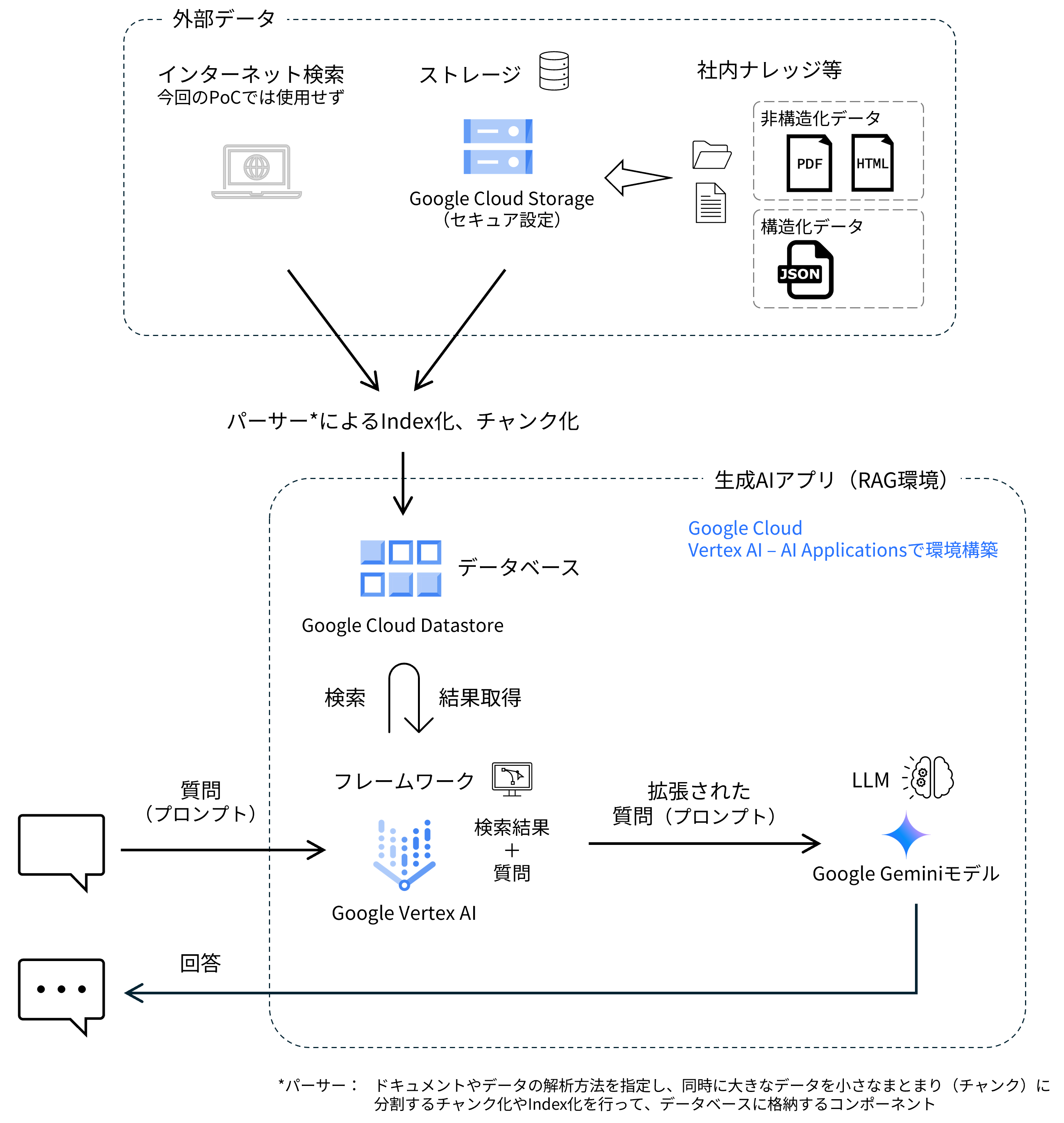
図2 PoCでGoogle Cloud上に構築した生成AIアプリ(RAG環境)全体像
方法
1. 業務の棚卸
生成AI(特にチャットボット)での効率化を念頭に、以下の2点について業務の棚卸を実施
■問い合わせ対応
ベテラン技術者に負荷がかかり、属人化していたプロダクトに関する問い合わせ対応を抽出
■開発アイテムの進捗状況確認
新任エンジニアが参画した際にコミュニケーションに時間がかかっていた開発進捗会での使用を想定
2. 生成AI導入のターゲットと必要データの決定
今回のPoCはアジャイル型で進めることとし、棚卸をした2つの業務をスプリントに定義。計画・実施検証・評価を高速に回し、スプリントゴールを目指しました。
| ターゲット | プロダクトに関する問い合わせチャットボット |
| 必要データ | 製品ドキュメント、マニュアル(PDF, HTML形式の非構造化データ) |
| ゴール | RAG環境構築とRAG性能、生成AI回答精度の検証 |
| ターゲット | 開発アイテムの進捗状況確認チャットボット |
| 必要データ | プロジェクト管理ツールRedmineのチケットデータ(JSON形式の構造化データ) |
| ゴール | RAG環境へのチケットデータの取込みフロー検討と生成AI回答精度の検証 |
3. 評価
スプリント1:非構造化データの評価(PDF、HTMLなど)
・RAG環境構築時のパーサー*を変更しながら、非構造化データを評価
・途中LLM自体のバージョンアップもあり、合計5バージョンの評価を実施
*パーサー:ドキュメントやデータの解析方法を指定し、同時に大きなデータを小さなまとまり(チャンク)に分割するチャンク化やIndex化を行って、データベースに格納するコンポーネント
スプリント2:構造化データの評価(JSONなど)
・プロジェクト管理ツールからの抽出チケット情報(JSON形式)をRAGシステムが認識しやすいJSONL形式に変換するツールを自作し、JSON化するカスタムフィールドを追加しつつ、LLMのバージョンの違いによる回答精度の確認も含め、合計8バージョンの評価を実施
どちらのスプリントにおいてもバージョン毎の評価を定量的に実施できるよう、評価用のデータセットを作成しました。今回作成したデータセットは質問(プロンプト)のみとし、回答についてはPoC参加メンバーによって検索性、網羅性、正確性を基準に評価しました。
結果
- スプリント1:プロダクトに関する問い合わせチャットボット
・完全自動化ではなく、回答を補助するアシスタントであれば十分対応可能
・完全自動化への阻害要因は、ドキュメント内の図の認識にある(パーサーの能力)
RAG環境に製品ドキュメントなどの非構造化データを投入する際、PoC当初はテキスト情報のみを抽出するOCRパーサー、見出し等のドキュメント構造を認識できるデジタルパーサーを使用していました。PoC期間中に「レイアウトパーサー」という新しいパーサーがリリースされ、表の認識が可能になりました。図についても一部認識が可能となり、当面はXMLやSVGなど、言語情報化された図であればRAG環境に投入できるようになりました。
- スプリント2:開発アイテムの進捗状況確認チャットボット
・チケット情報(JSON形式)の問い合わせに回答でき、多量の情報から検索・要約(把握)をする手間を省くことができる
・RAG環境に投入するチケット情報には、時系列情報とチケット同士の関連性(親子関係等)をJSONデータに含めることが肝要
製品バージョンアップ時のリリースノートなどドキュメント作成にも力を発揮し、リリース作業の軽減にもつながりました。
以上のことから、生成AIは、問い合わせ対応業務および、開発アイテムの進捗状況確認に適用可能という結果になりました。

RAG環境構築時のコツと注意点
- 今回のPoCで学んだ、生成AIを業務適用する際にRAG環境を構築する場合のコツと注意点は、以下の項目が挙げられます。
・RAG環境のデータベース部分はブラックボックスである場合がほとんどのため、定量的な評価基準(観点)を設けて評価を実施する - ・JSON等の構造化データをRAG環境に投入する場合、構造そのものがデータベースのカラム情報になるため、JSONのKeyが無いと検索にヒットせず、LLMが回答できないか誤りを含む回答をすることがある
- ・検索能力は生成AIのツールベンダーに依存する
今回使用したGoogle Cloud環境の場合、Googleの検索技術(セマンティック検索と呼ばれる”意味”を検索する技術)に負うところが大きい - ・LLMの回答精度は、外部データから取得した検索結果にコンテキスト情報を付加することにより精度が向上する
- ・LLMのバージョンアップ(進化)により回答精度は飛躍的に向上する
これらのことから、PoCの目的としたRAG環境の構築ノウハウを習得でき、適用業務領域については問い合わせ対応全般に適用可能という結果が得られました。問い合わせ対応については、社内ナレッジを含む業務はもちろん、インターネット検索を含む業務についても適用可能と判断しています。問い合わせ対応以外にもLLMの文章生成、要約能力が発揮できる分野にも適用可能性があると想定しており、次のPoC実施を計画しています。
展開
当社では今回のPoCから生成AIの業務適用は可能との結論を得て、業務効率の向上と負担の偏りを軽減し働き方改革につなげるべく、全社横断のワーキンググループを発足させました。
ワーキンググループでは、付加価値の創出プロセスに生成AIを組み込むことも視野に入れ、活動を開始しています。
最後に
生成AIの社内活用について関心や課題をお持ちのご担当者様にとって、本コラムが一つのヒントとなれば幸いです。
当社は、クラウド環境構築支援や生成AI導入支援サービスなど、優れた技術・サービスを持つパートナーと連携し、生成AIの業務への導入をサポートしています。課題の解決策をお探しの方や、生成AIの活用方法に関心のある方など、お気軽にご相談ください。